(과거 스터디에서 발표하기 위해 노션에 작성했던걸 이전한 자료입니다. 옮기는 과정에서 깨져있을 수 있음을 양해 부탁드립니다)
우선, CockroachDB란?
- CockroachDB는 트랜잭션 및 강력하게 일관된 key-value store에 구축된 분산 SQL 데이터베이스입니다.
- 수평확장이 용이하고, 강력하게 일관된 ACID 트랜잭션을 지원합니다.
- 데이터 구조화, 조작 및 쿼리를 위한 친숙한 SQL API를 제공합니다. (google spanner는 psql 드라이버 호환이 안되고, GCP에 종속되버리는 큰 단점이 존재)(cockroachdb는 postgresql을 지원)
- Spencer Kimbell, Peter Mattis, Ben Darnell 이렇게 세 명의 전직 Googler가 만든 회사라고 하는데 (좀 더 찾아보니 이 세분이 재직시절 Google Colossus, Gmail, Bigtable 등에도 관여했다는 썰이...)
SQL, Relational Sharding, NoSQL, NewSQL

newSQL에 대한 간략한 설명
지난번 Etcd 글에서 CAP theorem, 그리고 CAP 한계로 인해 나온 PACELC theorem 등을 설명드렸는데, 이론적으로 CAP 모두를 만족할 수 없다는걸 설명드렸습니다.
다만 이러한 한계를 CP시스템 속에서 A를 99.999%(CockroachDB, Spanner)까지 보장하면서 사실상 CAP 모두를 이룩한 NewSQL이 등장했습니다. 원래에도 현실에서 Availability 100%는 불가능하기에 CAP 모두를 이룬것이나 마찬가지인데, 뿐만아니라 분산환경에서의 트랜잭션, multi region을 모두 지원합니다. cockroachDB는 rocksDB, peddle 두가지를 모두 지원하는 양방향 호환성이나 다른 이슈들 때문에 spanner에 비해 성능은 조금 밀리지만, GCP에 종속적인 단점이 있는 spanner에 비해, 컬럼패밀리, postgresql 드라이버까지 지원하게 됨으로써 상당히 괜찮은 선택지가 되었습니다.
어디서 CockroachDB를 사용하고 있을까?(=성능 및 안정성 검증)
국외로는 DoorDash, SpaceX, Tesla, ebay 등 (doordash, spacex, tesla는 2015년 이전부터 사용한듯)
국내로는 devsisters, Riiid 와 같은 스타트업들이 사용하는중
CockroachDB는 언제 좋은 선택일까?
CockroachDB는 규모에 관계없이 안정적이고 사용 가능하며 정확한 데이터와 밀리 초의 응답 시간이 필요한 애플리케이션에 적합합니다. 최소한의 구성 및 운영 오버 헤드로 자동 복제, 재조정 및 복구하도록 구축되었습니다. 구체적인 사용 사례는 다음과 같습니다.
- 분산 또는 복제 된 OLTP(Online Transaction Processing)
- 다중 데이터 센터 배포
- 다중 지역 배포
- 클라우드 마이그레이션
- 클라우드를 위해 구축 된 인프라 이니셔티브
CockroachDB는 2ms 이하의 단일 행 읽기와 4ms 이하의 단일 행 쓰기를 반환하며, 쿼리 성능 최적화를위한 다양한 SQL 및 운영 튜닝 방법 을 지원합니다 .
overview
ACID
원자성: CockroachDB가 원자 트랜잭션을 배포하는 방법CockroachDB의 트랜잭션은 "All or Nothing"입니다. 트랜잭션의 일부가 실패하면 전체 트랜잭션이 중단되고 데이터베이스는 변경되지 않습니다. 트랜잭션이 성공하면 모든 변형이 가상 동시성과 함께 적용됩니다.
일관성: CockroachDB Beta Passes Jepsen Testing- 쓰기 : Raft 알고리즘을 통해서 ACID (non-locking distributed commit) (내부적으로 pebble/rocks db 사용해서 concensus state 저장)
- (읽기 트랜잭션은 MVCC 기반)
Isolation:SERIALIZABLECockroachDB의 트랜잭션은 가장 강력한 ANSI 격리 수준 인 serializable을 구현합니다 . 이것은 트랜잭션이 변칙을 초래하지 않음을 의미합니다. (snapshot isolation 또는 SSI 사용 / SSI가 default)
durability: Raft 합의 알고리즘CockroachDB에서 확인 된 모든 쓰기는 raft를 통해 대부분의 복제본 (기본적으로 최소 2 개)에서 일관되게 유지되었습니다 . 소수의 복제본 (일반적으로 1)에만 영향을 미치는 전원 또는 디스크 장애는 클러스터 작동을 방해하지 않으며 데이터 손실도 없습니다.
그 외
- 수평 확장성
- 쿼리가 분산됩니다.(내부적으로 distributed SQL 사용) 따라서 단일 쿼리의 전체 throughput이 node를 추가할때마다 향상됩니다. (전체 throughput은 클러스터의 노드 수에 대한 선형요소)
- survivability (이것 때문에 cockroach라 명명한듯)
- 범위 복제본은 짧은 지연 시간의 복제를 위해 단일 데이터 센터 내에 함께 배치 될 수 있으며 디스크 또는 시스템 오류에서 살아남을 수 있습니다. 일부 네트워크 스위치 장애에서 살아 남기 위해 랙에 분산 될 수 있습니다.
- 범위 복제본 데이터 센터 전력에서 점점 더 큰 장애 시나리오를 살아 남기 위해 점점 더 서로 다른 지역에 걸쳐 또는 지역 정전에 손실을 네트워킹 데이터 센터에 위치 할 수 있습니다 (즉 multi region 지원 → 하지만 이건 enterprize만 지원한다는 단점이...)
- 추가로...
- 임의의 데이터 영역을 구성 할 수 있습니다. 이를 통해 복제 요소, 저장 장치 유형 및 / 또는 데이터 센터 위치를 선택하여 성능 및 / 또는 가용성을 최적화 할 수 있습니다
Architecture



SQL Layer
클라이언트의 SQL 질의(주로 postgresql)를 내부적으로 사용하는 K/V로 변환합니다
Transaction Layer
ACID Transcaction(SSI/SI 중 선택. defualt는 SSI). 읽기 트랜잭션이 따로 있어서 읽기작업만 필요할때는 읽기 트랜잭션을 따로 써줘서 성능최적화 해주는게 좋습니다.
Distribution Layer
분산 처리의 시점이 되는 Distribution 계층은 해당 Range Leaseholder가 위치한 Node의 Replication 계층에게 KV 동작 수행을 요청합니다 (상위 계층에게는 데이터 저장소에 대한 추상화된 단일 인터페이스를 제공함과 동시에, 실제 데이터가 분산되어 저장된 Range를 추적하고 분산처리를 수행합니다.)
Replication Layer
KV 데이터의 묶음 단위인 Range를 Majority Node에 복제하여(이것도 뒤에서 설명) 분산 저장하는 역할을 수행합니다. 복제된 Range에 대한 Lease 관리를 위해 Raft 알고리즘이 사용됩니다.
Storage Layer
계층구조의 row level에서 K/V data를 물리적으로 Disk에 읽고 쓰는 역할을 수행합니다. 이때, CockroachDB는 내부적으로 pebble/RocksDB를 사용합니다
Transaction Layer
Isolation
SQL 표준은 네가지 격리수준을 정의합니다.
SERIALIZABLE
REPEATABLE READ
READ COMMITTED
READ UNCOMMITTED
다만 SQL 표준에 스냅숏 격리의 개념이 없기때문에(SQL 표준은 1975년 시스템 R의 격리수준 정의를 기반으로 하고 그 당시에는 스냅숏격리가 발명되지 않았기때문) 대신 표면적으로 비슷해보이는 반복읽기가 SQL표준에 정의되어있습니다. 이는 모호하고 부정확한 표준을 야기했습니다. 따라서 여러 데이터베이스가 반복 읽기를 구현하지만 이것들이 실제로 제공하는 보장에는 커다란 차이가 있습니다. 심지어 REPEATABLE READ만 해도 쓰기 스큐, 팬텀 등 다양한 아노말리가 발생
사실, 다들 아시다시피 Isolation level과 성능은 Trade-off 관계에 있습니다.
대부분의 DBMS는 중간정도의 isolation level을 채택하게되는데, 이 경우엔 아노말리(더 자세한 사항은 사이트를 참조)가 생길 수 있고 그런건 개발자가 피해서 코딩해야하는데 사실 쉽지않은 일.

뿐만아니라, ACIDRain과 같은 보안취약점을 발생시키게 됨으로, 성능을 조금 희생하는게 맞지 않냐는게 spanner와 cockroachDB가 가고 있는 길이 아닐까 합니다.
Consistency(일관성)
일관성은 CAP에서 선현성(Linearizability)을 의미합니다.
CockroachDB는 SQL 표준에 정의 된 가장 높은 격리 수준 인 직렬화 가능한 SQL 트랜잭션을 보장 합니다. 쓰기를 위한 Raft 합의 알고리즘과 읽기를위한 사용자 지정 시간 기반 동기화 알고리즘을 결합하여 이를 수행합니다.
- 저장된 데이터는 MVCC로 버전이 지정되므로 읽기는 읽기 트랜잭션이 시작될 때 표시되는 데이터로 범위를 제한합니다 .
- Write는 Raft 합의 알고리즘(spanner는 아마 multi Paxos)을 사용하여 서비스됩니다 . 합의 알고리즘은 대부분의 복제본이 업데이트가 성공적으로 커밋되었는지 항상 동의하도록 보장합니다. 업데이트(write)는 커밋 된 것으로 간주되기 전에 대부분(majority)의 복제본(기본적으로 3개 중 2개)에 도달해야합니다.
쓰기 트랜잭션이 그 이후에 시작되는 읽기 트랜잭션을 방해하지 않도록하기 위해 CockroachDB는 또한 진행중인 트랜잭션에서 데이터를 마지막으로 읽은 시간을 기억 하는 타임 스탬프 캐시를 사용합니다. 이를 통해 클라이언트가 다른 동시 트랜잭션과 관련하여 항상 직렬화 가능한 일관성을 관찰할 수 있습니다.
Atomicity(원자성)
(여기서 부터는 cockroachDB Blog를 참고하였는데 2015년 글이라... 내부적으로 바뀌었을 수 있습니다. 이점 양해부탁드립니다)
원자성은 다음과 같이 정의됩니다
데이터베이스 명령어의 그룹이 실행되면, 모든 명령이 적용되거나 하나도 적용되지 않아야 함. (=all or nothing)
원자성이 없으면, 인터럽트된 트랜잭션은 의도한 변경사항의 일부만 적용할 수 있습니다. 이것은 데이터베이스가 일관성 없는 상태로 남을 여지를 줍니다.
전략
원자 트랜잭션을 제공하기 위해 CockroachDB가 사용하는 전략은 다음 기본 단계를 따릅니다.
Switch어떤 키의 값을 수정하기 전에, 트랜잭션은 변경되는 실제 값과 구별되는 쓰기가능한 값인 switch를 만듭니다. switch에는 동시에 접근할 수 없습니다. switch의 Read 및 Write는 엄격하게 순차적으로 실행됩니다. switch는 초기에 'off' 상태이며, 'on'상태로 스위치 할 수 있습니다.
Stage데이터베이스 대한 변경사항들을 준비하지만, 기존에 존재하는 어떤 값도 덮어쓰지 않습니다. 대신, '새 값'이 '기존 값'에 근접하여 stage됩니다.
FilterStage된 값이 있는 키의 경우, 해당 키에 대한 Read는 값을 반환하기 전 트랜잭션의 Switch 상태를 확인합니다. 만약 스위치가 'off' 상태이면, '기존 값'을 반환합니다. 스위치가 'on'이라면 'stage된 값'을 반환합니다. 따라서 'stage된 값'이 있는 키의 모든 Read는 switch 상태를 통해 필터됩니다.
Flip작성자가 트랜잭션의 모든 변경사항을 준비하면, switch를 'on'상태로 전환합니다. 필터링과 함께 트랜잭션의 일부로 준비된 모든 값은 향후 Read에서 즉시 반환됩니다.
Unstage트랜잭션이 완료되면(중단되거나 커밋되면), 즉시 Stage된 값이 가능한 빨리 정리됩니다. 트랜잭션이 성공하면 '기존 값'이 '준비된 값'으로 대체됩니다. 실패하면 '준비된 값'은 무시됩니다. 언스테이징은 비동기식으로 수행되며 트랜잭션이 커밋된 것으로 간주되기 전에 완료될 필요가 없습니다
The Detailed Transaction Process
Switch : CockroachDB 트랜잭션 레코드
트랜잭션을 시작하려면, 먼저 트랜잭션 레코드를 만들어야 합니다. 트랜잭션 레코드는 CockroachDB가 Switch를 제공하는 데 사용됩니다.
각 트랜잭션 레코드에는 다음 필드가 있습니다:
- 트랜잭션을 식별하는 고유 ID(UUID)
- 현재 상태(
PENDING,ABORTED,COMMITTED)
- cockroach K/V 키 (이것은 분산 데이터 저장소에서 switch의 위치를 결정합니다.)
PENDING 상태의 새로운 UUID를 사용하여 레코드를 생성합니다. 그런 다음 CockroachDB의 BeginTransaction()을 사용하여 트랜잭션 레코드를 저장합니다. 레코드는 트랜잭션 레코드의 키에 함께 배치됩니다. (즉, 분산 시스템의 동일한 노드에 있음)
레코드가 하나의 cockroach 키에 저장되기 때문에, 그것에 대한 작업은 엄격하게 순차적으로 실행됩니다. (Raft와 스토리지 엔진의 조합으로 인해 가능합니다.) 트랜잭션의 상태는 스위치의 켜짐/꺼짐 상태이며 PENDING 또는 ABORTED 상태는 꺼짐을, COMMITTED는 켜짐을 나타냅니다. 따라서 트랜잭션 레코드는 스위치의 요구사항을 충족시킵니다.
트랜잭션 상태는 PENDING에서 ABORTED 또는 COMMITTED로 변경될 수 있지만, 다른 방법으로 변경될 수는 없습니다. (즉, ABORTED와 COMMITTED는 영구 상태입니다.)
Stage : Write Intent
트랜잭션에서 변경을 스테이지하기 위해 CockroachDB는 write intent라고 하는 자료구조를 사용합니다. 값이 트랜잭션의 일부로 키에 기록될 때마다 write intent로 기록됩니다.
이 write intent 자료구조에는 트랜잭션이 성공할 경우 기록될 값이 들어있습니다.
또한 write intent에는 트랙잭션 레코드가 저장된 키도 포함됩니다. 이것은 읽기 작업시 write intent를 발견하면 이 값을 이용해 트랜잭션 레코드(스위치)를 찾을 수 있기 때문에 중요합니다.
마지막으로, 모든 키는 단 하나의 write intent를 가집니다. 만약 동시에 여러개의 트랜잭션이 있는 경우 한 트랜잭션이 다른 활성화된 intent를 가진 트랜잭션에 쓰기 시도를 할 수 있게 됩니다. 여기서는 한 번에 하나의 트랜잭션만 있다고 가정하며(아마 MVCC, SSI 등이 너무 복잡해서 간단하게 설명하려고 하는듯), 이미 존재하는 트랜잭션의 write intent는 폐기하는것으로 가정하고 설명하겠습니다.
이미 write intent가 있는 키에 쓰는 경우
- 기존 intent에 대한 트랜잭션 레코드가
PENDING상태인 경우ABORTED상태로 변경합니다. 이전 트랜잭션이COMMITTED또는ABORTED인 경우 아무 작업도 하지 않습니다.
- 이전 트랜잭션에서 기존 intent를 정리하고, 제거합니다.
- 현재 트랜잭션에 새 intent를 추가합니다.
Filter : Intent 읽기
키를 읽을 때, 스위치의 상태를 참조하여 값을 반환하기 전에 세가지 원칙을 꼭 따라야 합니다.
만약 키가 일반 값이면(write intent가 없다면), 키와 관련된 진행중인 트랜잭션이 없고, 가장 최근 커밋된 값이 있음을 알 수 있습니다. 따라서 값은 그대로 반환됩니다.
그러나 write intent를 만난다면, intent를 제거하기 전에 트랜잭션이 취소되었다는 것을 의미합니다.(한 번에 하나의 트랜잭션만 있다고 가정 중입니다.). 따라서, 읽기 작업을 계속하기 전에 트랜잭션의 스위치(트랜잭션 레코드) 상태를 확인해야 합니다.
- 만약 트랜잭션 레코드가
PENDING상태라면ABORTED로 변경합니다.
- 이전 트랜잭션에서 기존 intent를 정리하고, 제거합니다.
- 키의 일반 값을 반환합니다. 이전 트랜잭션이
COMMITTED인 경우 정리 작업은 스태이지 된 값을 일반 값으로 업그레이드 합니다. 그렇지 않다면 트랜잭션 이전의 기존 값을 반환합니다.
Flip : 트랜잭션을 커밋
트랜잭션을 커밋하기 위해, 트랜잭션 레코드가 COMMITTED 상태로 업데이트됩니다.
트랜잭션에 의해 작성된 모든 write intent는 즉시 유효합니다. 이 트랜잭션에 대한 write intent를 만나는 모든 READ는 트랜잭션 레코드를 통해 필터링되고, 커밋되었는지 확인하고, intent에 스테이징된 값을 반환합니다.
트랜잭션 Aborting
트랜잭션의 상태를 ABORTED로 변경하에 트랜잭션을 중단할 수 있습니다. 이 시점에서 트랜잭션은 영구적으로 중단되고 향후 읽기는 이 트랜잭션에 의해 작성된 write intent를 무시합니다.
Unstage : intent 정리
위의 시스템은 이미 원자성 커밋 속성을 제공합니다. 그러나 필터링 단계는 중앙 위치(트랜잭션 레코드)를 통해 필터링 하기위해 분산 시스템 전체에 쓰기가 필요하기 때문에 Filter 비용이 많이 듭니다. (분산시스템에 바람직하지 않음)
따라서, 트랜잭션이 완료된 후 가능한 한 빨리 작성된 write intent를 제거합니다. 키에 write intent가 없는 일반 값이 있는 경우, 읽기 작업을 필터링할 필요가 없으므로 적절히 분산된 방식으로 처리됩니다.
Cleanup Operation
연관된 트랜잭션이 PENDING 상태가 아닐때, write intent는 정리 작업을 호출할 수 있습니다. 이는 다음 단계를 따릅니다.
- 트랜잭션이
ABORTED인 경우, write intent는 제거됩니다.
- 트랜잭션이
COMMITTED이면, write intent의 'staged 값'은 키의 `plain 값'으로 변환되고, write intent는 제거됩니다.
- 정리작업은 멱등적입니다. 즉, 두 프로세스가 동일한 키와 트랜잭션에 대한 intent를 정리하려고 하면 두 번째 작업은 작동하지 않습니다.
정리는 다음과 같은 경우에 수행됩니다:
- WRITE작업이 트랜잭션을 커밋하거나 중단한 후, 즉시 모든 intent를 정리합니다.
- WRITE작업이 이전 트랜잭션의 다른 write intent를 만났을 때.
- READ작업이 이전 트랜잭션의 write intent를 만났을 때.
만료된 write intent를 여러 경로를 통해 정리함으로써, 필터링으로 발생되는 성능영향이 최소화됩니다.
Durability
CockroachDB는 서버 재시작부터 데이터 센터 중단에 이르기까지 소프트웨어 및 하드웨어 장애에서 살아남도록 설계되었습니다. 이는 다른 분산 시스템 (예 : 부실 읽기)의 일반적인 혼동 아티팩트없이 강력하게 일관된 복제와 장애 후 자동 복구를 사용하여 수행됩니다.
복제
CockroachDB는 가용성을 위해 데이터를 복제 하고 Paxos 의 인기있는 대안인 Raft 합의 알고리즘을 사용하여 복제본 간의 일관성을 보장합니다. 보호하려는 장애 유형과 네트워크 토폴로지에 따라 다양한 방법으로 복제본의 위치를 정의 할 수 있습니다 . 다음에서 복제본을 찾을 수 있습니다.
- 서버 장애를 허용하는 랙 내의 다양한 서버
- 랙 전원 / 네트워크 장애를 허용하기 위해 데이터 센터 내의 서로 다른 랙에있는 서로 다른 서버
- 대규모 네트워크 또는 정전을 허용하기 위해 서로 다른 데이터 센터에있는 서로 다른 서버
여러 지역에 분산 된 CockroachDB 클러스터에서 지역 간의 왕복 대기 시간은 데이터베이스 성능에 직접적인 영향을 미칩니다. 이러한 경우 각 테이블의 대기 시간 요구 사항을 고려한 다음 적절한 데이터 토폴로지 를 사용하여 최적의 성능과 복원력을위한 데이터를 찾는 것이 중요합니다 . 단계별 데모는 저 지연 다중 리전 배포를 참조하십시오 .
자동 수리
서버 재시작과 같은 단기 오류의 경우 CockroachDB는 Raft를 사용하여 대부분의 복제본을 사용할 수있는 한 원활하게 계속합니다. Raft는 이전 리더가 실패 할 경우 각 복제본 그룹에 대한 새로운 "리더"를 선택하여 트랜잭션을 계속할 수 있고 영향을받은 복제본이 온라인 상태가되면 해당 그룹에 다시 참여할 수 있도록합니다. 서버 / 랙이 장기간 다운되거나 데이터 센터가 중단되는 등 장기적인 장애의 경우 CockroachDB는 영향을받지 않는 복제본을 소스로 사용하여 누락 된 노드의 복제본을 자동으로 재조정합니다. 가십 네트워크의 용량 정보를 사용하여 클러스터의 새 위치를 식별하고 누락 된 복제본은 사용 가능한 모든 노드와 클러스터의 총 디스크 및 네트워크 대역폭을 사용하여 분산 방식으로 복제됩니다.
MultiRaft
CockroachDB는 Raft를 사용하여 Node가 고장났을 때도 데이터가 일관성을 유지하게 합니다. etcd 및 Consul과 같이 Raft를 사용하는 대부분의 시스템에서 전체 시스템은 하나의 Raft consensus 그룹으로 이루어집니다. 하지만 CockroachDB에서는, Range들로 데이터가 나뉘며, 각각 자체 Raft consensus 그룹을 가집니다. 즉, 각 노드가 수십만 개의 Raft consensus 그룹으로 나누어질 수 있습니다. 이러한 문제를 cockroachDB는 MultiRaft라고 부르는 계층을 Raft 위에 도입하여 해결했습니다.
단일 Range에서 (3개 또는 5개 노드 중) 하나가 리더로 선출되고, 주기적으로 팔로워에게 heartbeat message를 보냅니다.
시스템이 더 많은 Range를 포함하도록 증가함에 따라, heartbeat를 처리하는데 필요한 트래픽 양도 증가합니다.

Range 수가 Node 수보다 훨씬 많기때문에(Range 수를 작게 유지하면 노드가 실패할때, 복구시간이 개선하는데 도움이 됨) 따라서, 중복되는 Range가 많아집니다. 이때 MultiRaft가 등장합니다. 각 Range에서 독립적인 Raft로 처리하는게 아니라, 전체 노드의 Range를 그룹으로 관리합니다. 아무리 많은 Range가 있더라도, 각 노드 쌍은 틱(tick)당 heartbeat를 한번만 교환하면 됩니다.


heartbeat 네트워크 트래픽을 줄이는 것 외에도 MultiRaft는 다른 영역의 효율성도 향상시킬 수 있습니다. 예를 들어, MultiRaft는 Range 당 하나의 goroutine 대신 작고 일정한 수의 goroutines(현재 3 개) 만 필요합니다.
(multiraft 부분은 CoreOS의 Etcd팀과 협력해서 이 부분을 작업했다는 썰이...)
How to Read and Write?
Read & Write(with Lease holder way)
Read Scenario

- 노드 2 (게이트웨이 노드)는 표 3에서 읽기 요청을 수신합니다.
- 테이블 3의 임대 소유자는 노드 3에 있으므로 요청이 여기로 라우팅됩니다.
- 노드 3은 데이터를 노드 2로 반환합니다.
- 노드 2는 클라이언트에 응답합니다.
관련 범위에 대한 임대 보유자가있는 노드에서 쿼리를 수신하면 네트워크 홉 수가 더 적습니다.
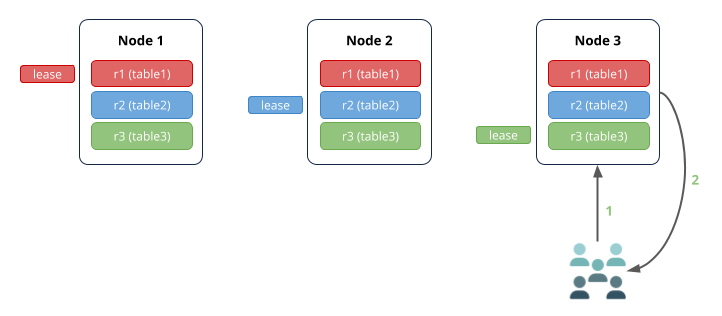
Write Scenario

- 노드 3 (게이트웨이 노드)은 테이블 1에 쓰기위한 요청을 수신합니다.
- 테이블 1의 임대 보유자는 노드 1에 있으므로 요청이 여기로 라우팅됩니다.
- 임대 소유자는 Raft 리더와 동일한 복제본 (일반)이므로 자체 Raft 로그에 쓰기를 동시에 추가하고 노드 2 및 3의 팔로워 복제본에 알립니다.
- 한 팔로워가 Raft 로그에 쓰기를 추가하면 (따라서 대부분의 복제본이 동일한 Raft 로그를 기반으로 동의 함) 리더에게 이를 알리고 동의하는 복제본의 키-값에 쓰기가 커밋됩니다. 이 다이어그램에서 노드 2의 추종자는 쓰기를 승인했지만 노드 3의 추종자 일 수도 있습니다. 또한 합의 계약에 참여하지 않은 추종자는 일반적으로 다른 추종자 직후에 쓰기를 수행합니다.
- 노드 1은 노드 3에 대한 커밋 승인을 반환합니다.
- 노드 3은 클라이언트에 응답합니다.
읽기 시나리오에서와 같이 관련 범위에 대한 임대 소유자 및 Raft 리더가있는 노드에서 쓰기 요청을 수신하면 네트워크 홉 수가 더 적습니다.

그 외 방식(Quorum reads, strongly consistency quurom reads...)


Bottleneck to Read performance
Read는 Lease Holder에 의해 실행되기에 bottleneck이 발생할 수 밖에 없는 구조.
⇒ 따라서 Lease Holder에게 과부하가 걸림
partition / range splitting 하면 되잖아?
range splitting되면 분산 트랜잭션의 비율이 증가하고, 올바른 파티셔닝 전략이 어려워짐.
그리고, 어차피 핫스팟 파티션으로 인해 여전히 Read bottleneck이 발생
그러면 read-heavy한 환경에서 어떻게 최적화를 가능하게 할까?
아래에서 설명...
Improving Read Scalability

우선, Raft는 정족수를 사용해 wirte를 커밋합니다
Raft를 사용했기에 majority quorum에서 Read!
Lease holder와 Read 결합
따라서 정리해보자면,
Step Of Quorum Read
- 노드의 majority에 Read 요청 보내기
- 요청받은 노드는 timestamp에 상응하는 latest value를 응답.
- latest timestamp에서 value를 선택!

+ (글을 작성한지 2년이 지난 2023.05.20 현재 paxos 가 이 방식을 채택했다.)
참고 : link
CockroachDB는 어떻게 확장됩니까?
CockroachDB는 최소한의 운영자 부담으로 수평으로 확장됩니다. 로컬 컴퓨터, 단일 서버, 기업 개발 클러스터 또는 사설 또는 공용 클라우드에서 실행할 수 있습니다. 용량 추가 는 실행중인 클러스터에서 새 노드를 가리키는 것 만큼 쉽습니다.
키-값 수준에서 CockroachDB는 하나의 빈 범위로 시작합니다. 데이터를 입력하면이 단일 범위는 결국 임계 값 크기 (기본적으로 512MiB)에 도달합니다. 이 경우 데이터는 전체 키-값 공간의 연속 세그먼트를 포함하는 두 범위로 분할됩니다. 이 프로세스는 무기한 계속됩니다. 새로운 데이터가 유입됨에 따라 기존 범위는 계속해서 새로운 범위로 분할되어 상대적으로 작고 일관된 범위 크기를 유지하는 것을 목표로합니다.
클러스터가 여러 노드 (물리적 머신, 가상 머신 또는 컨테이너)에 걸쳐있는 경우 새로 분할 된 범위는 용량이 더 많은 노드로 자동 재조정됩니다. CockroachDB 는 노드가 네트워크 주소, 저장 용량 및 기타 정보를 교환하는 피어-투-피어 가십 프로토콜 을 사용하여 재조정 기회를 전달 합니다.
요약 + 추가적으로 지원하는것들
| 이름 | 열 |
|---|---|
| PostgreSQL wire 호환성 | 대부분의 사용 가능한 PostgreSQL 도구를 통해 친숙한 관계형 개념 사용 |
| ACID SQL 트랜잭션 | row-level에서 ACID 모두 보장 |
| Native JSONB Support | 일관성을 유지하면서 비즈니스 유연성을 위해 반 구조화된 데이터 저장 |
| Spatial data types & indexing | Store and index Spatial data types with familiar, PostGIS-compatible SQL syntax |
| 쿼리 최적화 | SQL을 수동으로 튜닝 할 수 있는 자동 쿼리 최적화 및 유연성 확보 |
| Active dynamic schema changes | 애플리케이션에 다운 타임이나 부정적인 결과없이 테이블 스키마 업데이트 |
| Cost-based optimizer | 자동 생성 된 통계를 통해 수천 개 중에서 가장 성능이 좋은 쿼리 계획을 가져옵니다. |
| Locality-aware cost-based optimizer | Serve low-latency, consistent, and current reads from the closest data |
| Follower reads | Serve low-latency, consistent, historical reads from the closest data |
| column family 지원 | |
| 느린 사망선고 |
References
- sites
- presentations/research